If this sounds familiar, you’re not alone. Across Europe, 44% of employees now work in hybrid setups and 14% work on a full remote schedule (Eurofound, 2025). That’s close to 60% of the workforce juggling calendars, notifications and collaboration in a mostly digital environment.
On paper, distributed teams seem to have everything they need to work well. And yet, despite having Slack channels, shared drives and synced calendars, many teams still feel stuck in a cycle of repetitive video calls, endless email threads and barely any time for focused work.
It’s clear then that the difference between teams that thrive remotely and those that burn out isn’t more tools, it’s better rhythms.
At New Verve Consulting, we’ve spent years helping hybrid and remote teams build working practices that stick. Here’s what we’ve learned, and how you can design a remote work week that feels less chaotic and more human.
Rhythm matters more than tools
A well-designed remote week isn’t overloaded with meetings or rigid schedules. It’s structured enough to give clarity, but flexible enough to allow for real focus. It protects thinking time, fosters visibility without micromanagement, and most importantly, it keeps people at the heart of the process.
One of the biggest mindset shifts we’ve seen? Treating focus like something you actively protect. Blocking out quiet hours, agreeing on no-meeting mornings, or simply letting people manage their own diaries can go a long way. It’s not about isolating individuals, it’s about creating an environment where progress can actually happen, and the benefits of remote work can be felt.
A 2025 Gartner study found that high-performing remote teams spend 30% less time in meetings and 25% more time on focused work, thanks to intentional scheduling practices.
These teams adopted simple but powerful habits: setting clear boundaries for collaborative time and deep work, enforcing “meeting-free” windows during peak focus hours, and reducing unnecessary status updates by relying on shared dashboards and asynchronous check-ins.
Gartner’s data also revealed a strong link between these practices and team performance:
- Teams with fewer meetings reported 22% higher project delivery speed.
- Employees in these teams experienced 35% lower levels of reported burnout compared to teams with unstructured schedules.
- Focused work time directly correlated with higher creativity scores, suggesting that protecting deep work isn’t just about efficiency but also about enabling innovation.
The takeaway? Meetings aren’t inherently bad, but without a clear rhythm, they can eat into the time teams need to deliver meaningful results.
Know when to talk, and when to write
One of the biggest points of friction in hybrid teams is deciding what needs real-time discussion and what doesn’t.
Not everything deserves a meeting, and not every update should be buried in a long thread.
Teams that get this balance right create space for deep thinking without falling out of sync. Calls are saved for collaboration and alignment. Everything else (updates, feedback, handovers) goes in writing, in shared spaces that everyone can access when it suits them.
Show your work even when it’s messy
In a shared office, you pick up on work in progress without even thinking about it. You see screens, hear snippets of conversation, and sense momentum. That doesn’t happen by default in a remote set-up.
Which means visibility has to be intentional. Sharing early drafts, working out loud, and using shared project boards helps the whole team stay aligned, without resorting to constant check-ins. It’s not about tracking people. It’s about building shared direction.
According to Microsoft’s 2025 Work Trends Index, teams with high “work visibility” where progress, decisions and responsibilities are transparent to everyone reported 23% higher engagement and delivered projects 18% faster than teams with poor visibility.
The study found that in distributed environments, lack of visibility often leads to:
- Duplicated effort, where multiple people unknowingly work on the same task.
- Decision bottlenecks, because team members don’t know who owns what.
- Low morale, as individuals feel their contributions aren’t recognised.
In contrast, teams that embraced “working in public” habits (like sharing early drafts, using collaborative boards and documenting decisions openly) enjoyed:
- Stronger alignment, with 42% fewer missed deadlines.
- Higher innovation scores, thanks to early feedback loops.
- Better wellbeing, with 31% fewer reports of “feeling out of the loop.”
Connection isn’t a nice-to-have
Remote teams don’t just need clarity. They also need connection.
When everything becomes transactional: tasks, updates, deadlines, etc. it’s easy to forget there are humans on the other side of the screen. The best remote teams we’ve seen create space for the human side of work.
That might be a light check-in on Monday, a casual “coffee drop-in” on Friday, or simply calling out someone’s win in the team chat. It doesn’t have to be formal. It just has to be genuine.
What can you try next week?
Here are five small but powerful shifts to test with your team:
- Block out two “focus windows” with zero meetings or pings
- Start Monday with an async check-in (no live call)
- Use a shared board to track work in progress, drafts included
- Decide as a team what needs a meeting and what doesn’t
- Celebrate one team win, big or small, on Friday
Good weeks don’t happen by chance, they’re designed
When remote weeks feel chaotic or reactive, it’s rarely about the people. It’s almost always a sign there’s no rhythm in place, just decisions, updates and expectations handled on the fly.
The good news? You don’t need to overhaul everything. A few shared habits and a bit of thoughtful structure can go a long way.
Want to design a remote work week that actually works? We’d love to help. At New Verve Consulting, we work with teams to shape collaboration practices that support the way they work, rather than getting in the way. Get in touch today for a free 30-minute consultation. No pitches, just real conversation about your team’s needs.
Keeping track of social posts, email marketing, and reporting, all while managing multiple projects and meeting specific deadlines can be daunting for creative teams. This is where Trello comes in, with its visual approach to project management; features such as boards, lists and cards offer a flexible and intuitive way to organise workflows. In our experience as a team, Trello has been central in fuelling collaboration between users and allowing us to implement our strategy through a creative process.
Wondering how your creative team can leverage Trello’s features to not only manage but also streamline their process? In this blog, we will investigate some of the main features that Trello offers and how your team can take advantage of them.
Why choose Trello?
With the wealth of productivity tools available, teams may encounter challenges in selecting software that aligns with their needs. What really makes Trello stand out from the rest are the platform-specific Power-up integrations and templates designed to assist your team with crafting their workflow and executing their projects. As a tool that focuses strongly on the visual representation of tasks, it is only natural for creative teams to incorporate this tool into their process.
Take your creative process to the next level with Kanban boards
Creative projects often consist of many moving parts, making it difficult for teams to collaborate effectively without facing any roadblocks along the way. This is where adopting a Kanban method can be extremely helpful. Trello is underpinned by Kanban project management principles, which prioritise visualisation and the establishment of a continuous workflow, enabling teams to approach their project in an intuitive manner.
Trello simplifies this by creating a framework which allows users to customise boards, lists and cards to reflect their project needs. For instance, a creative team may need to balance keeping track of their tasks alongside which outlet they plan to deliver the final product, all while staying mindful of approaching deadlines. This is made straightforward by Trello, in which teams can divide the board based on categories that meet their specific needs. This could include the columns: Creative Proposals, To-Do, In Progress, In Review and Done. Moreover, visual cues such as tags, labels and colour-coding can be used to populate each card and provide more context for the task at hand.
As a card progresses through the board, members of the team can easily pick up information from each ticket at a glance through strong visualisation. This fosters alignment across the team and provides a comprehensive overview of the tasks in the scope of their strategy, along with the channels slated for implementation.
Enhance collaboration
Creative teams run on effective collaboration. Any creative process is boosted by the input of multiple team members, and Trello provides the landscape for this to become a reality. Trello cards allow users to capture ideas in an actionable format by breaking down complex projects into simple tasks that users can comment on and interact with. In addition to this, tasks can be assigned to different team members to keep track of accountability and avoid roadblocks caused by miscommunication. By having a centralised point of all communication and resources, teams skip the hassle of engaging with multiple sources for one piece of information, streamlining their process. Trello exists to facilitate seamless collaboration, no matter where or when.
Integrations with Power-Ups
Trello boards create the perfect space for creative teams to store and manage content, all while keeping track of their workflow. Unlike many other teams, those working in the creative space need to have the capabilities for content management, which may include different iterations of copy, campaign artwork or photos. This is made possible not only by Trello’s extensive features but also enhanced through their Power-Up integrations.
These integrations allow users from all over the creative scope, from designers to marketers, to manage their processes in a productive way. On the marketing side, integrations with tools such as Slack and Mailchimp allow teams to bridge the gap between business objectives and customer response. Those within the design space on the other hand may benefit from integrations with tools such as Adobe Creative Cloud, which allows you to design campaign prototypes without having to leave Trello. These integrations ensure that the entire team is able to provide input in an intuitive way.
Fuelling creativity while staying flexible
Trello provides creative teams with the landscape and facilities that bring their ideas to life, all while making it easy to keep track of progress and deadlines along the way. Whether you’re brainstorming a new campaign, keeping track of your audience, or working on new visuals, Trello allows you to move seamlessly through your process while keeping the team aligned. Wondering how this compares to Atlassian’s project management tool, Jira? When it comes to implementing a tool with a variety of use cases, Trello may be your answer. However, if your team is looking for a tool with more structure and higher complexity, Jira may prove to be a more viable solution.
If you would like to know more about how your team can use Trello to boost their creative process, get in touch!
]]>
As the date for Atlassian’s highly anticipated Team ‘24 event draws nearer, your team may be wondering what’s in store. Taking place in Barcelona, Spain from the 8-10th of October, the conference will be packed full of the newest developments and insights Atlassian has to offer. From inspiring keynotes to breakout sessions and product releases, attendees will have the opportunity to gain valuable industry knowledge from leading European brands first-hand. Unable to attend the event in person? Atlassian has you covered, their free digital pass gives teams access to exclusive content like sessions, along with product demos and customer stories.
What does Atlassian have in store?
Taking place over three days, teams can rest assured that there will be something for everyone. Key developments, such as the new AI teammate, Rovo, will be explored through inspiring keynotes delivered by industry experts. Be prepared to discover how Atlassian’s latest AI tools can drive your team’s efficiency and accelerate your business growth. Designed to aid your team in finding information across multiple SaaS apps, users will be able to seamlessly retrieve and expand on knowledge as they work. In addition to this, the introduction of Rovo Agents empowers teams to delegate complex tasks, spanning from workflow management to maintenance. These AI developments are sure to bolster more effective collaboration across teams, in line with Atlassian’s fundamental principles.
Furthermore, exciting developments in the Atlassian Cloud platform will be highlighted, alongside discussions regarding the anticipated evolution of Data Center to provide continued support for those not yet prepared for migration. Attendees can expect to learn how Atlassian’s commitment to enterprise resiliency is showcased through their continued growth and understanding of upcoming changes in the security landscape and the rise of AI’s role in the workplace. Innovations within the Cloud platform, such as novel intelligence, cross-functional collaboration, automation and analytics capabilities will also be a key focal point for the event.
Following Atlassian’s previous announcement of their plan to reposition their products as a platform for enterprises and businesses, teams can expect to gain a unique perspective on continued growth with their System of Work. In fact, the focus on tightening integrations between tools within the Atlassian ecosystem is an exciting development, likely to fuel greater autonomy within teams.
Interested in what our team is most looking forward to? Here is what New Verve has to say:
“I’m most looking forward to 1:1s and the opportunity to connect with other attendees. I think there will be plenty to talk about considering the information Atlassian will give at various sessions, particularly around AI and Rovo.”
Louise Reilly, Head of Communications and People.
“Team is always a fantastic opportunity to build lasting relationships which strengthen our ecosystem - I look forward to getting together with fellow attendees whom I otherwise might not have crossed paths with, be it customers, fellow partners, or Atlassians themselves.”
Kris Siwiec, Head of Solutions and Services.
“I am looking forward to the keynote by Arsène Wenger. Also eager to connect with industry leaders, network with peers, and meet loads of customers.”
Tushar Singh, Sales Manager.
Make sure to secure your tickets for the chance to watch Atlassian leadership unveil the latest visionary announcements in real-time. If you would like to hear our team’s unique perspective or to meet us at the event, get in touch with hello@newverveconsulting.com
]]>
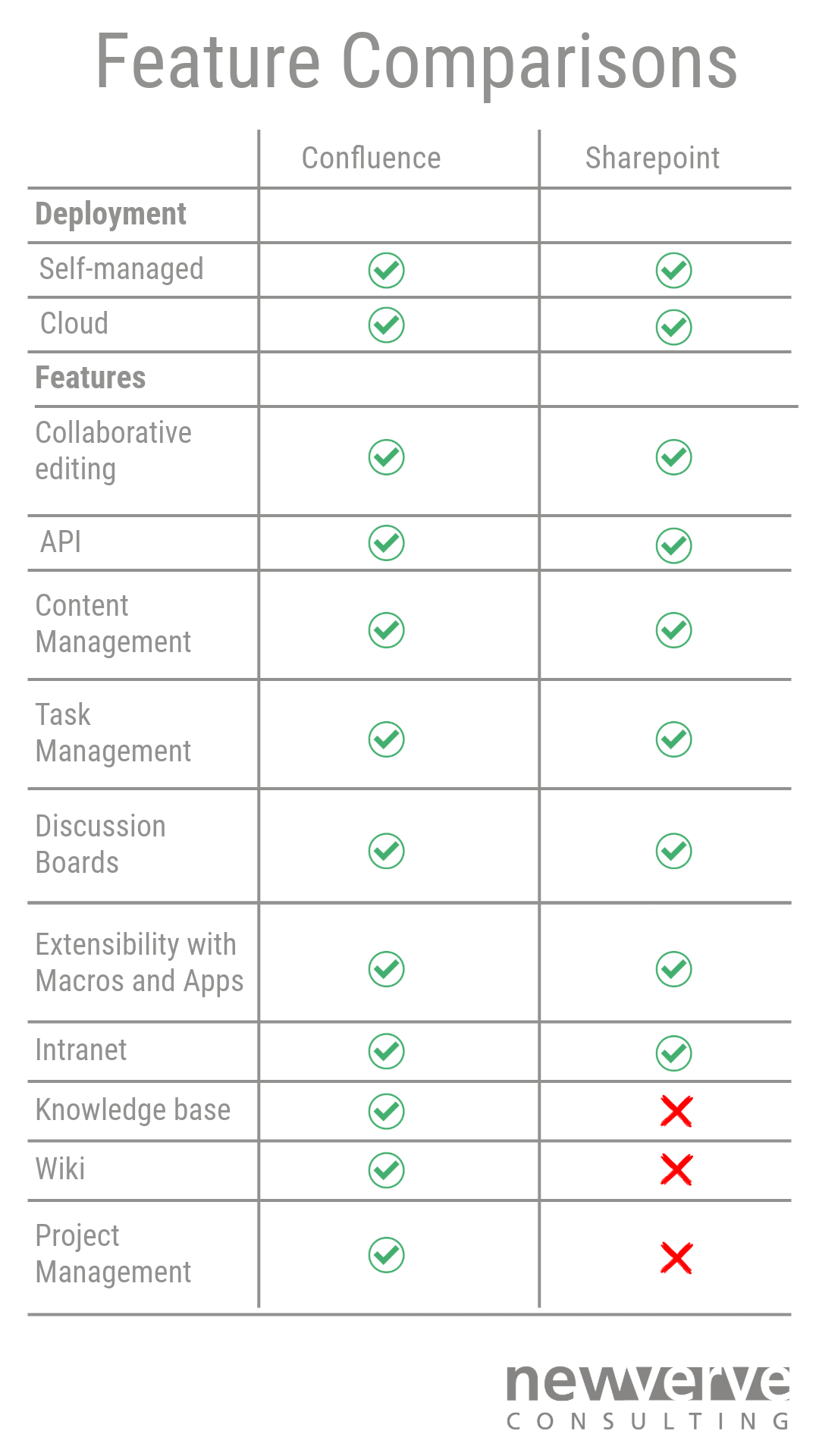
With the wealth of collaborative products available within today’s digital landscape, narrowing down which tool is right for your team can be difficult. Confluence and Sharepoint are among the most widely utilised solutions, catering not only to the needs of software teams but a diverse range of organisations. In this blog, we will guide you through the advantages and drawbacks of each software, taking into account the distinct features that set these platforms apart. Read on to make your decision on what’s right for your team!
Confluence and SharePoint: At a Glance
Before we get started, it’s important to consider what both products are designed for. Confluence, a tool created by Atlassian, serves as a web-based, collaborative workspace centred around efficient documentation and knowledge management. Primarily used by software teams, Confluence pages can be used to create, capture and collaborate on projects through an open-plan platform.
Microsoft’s SharePoint, on the other hand, exists as a content management system designed to facilitate the storage and distribution of company files through a centralised location. With slightly more customisable features, SharePoint’s platform allows for more intensive configurations of libraries, workflows and user permissions.
How do Confluence and Sharepoint compare?
User Features and Interface
First of all, let’s look at the features offered by Confluence and Sharepoint respectively.
Designed to be straightforward, Confluence exists as a digital platform where teams can store files and projects in “spaces”. Such spaces allow team members to collaborate and share information through pages and subpages, keeping their content organised in meaningful categories with high visibility. This makes for an intuitive way of sharing rich information such as videos, files or links Jira issues, and macros with ease. In terms of editing documents, Confluence allows users to file, incline and leave page comments with its robust collaboration capabilities. Document sharing is made easy with a wide variety of formats, such as pdfs, documents and images, meaning that team members always remain within the feedback loop.
Where Confluence can fall short however is its lack of customisations compared to platforms such as Sharepoint. Depending on the needs of your team, Sharepoint boasts a more complex and customisable interface. Unlike Confluence, Sharepoint is built around a series of internal websites named “team sites”. These sites offer a wider range of features such as metadata and check-in/check-out, which are designed to facilitate a larger volume of documents. The advancement of Sharepoint’s features can be both a pro and a con, while it is well-suited to larger corporations, its extensive and unintuitive interface may pose challenges for non-technical users.
Integrations
With both Confluence and SharePoint providing their platform-specific integrations, your choice should be informed by your team’s size and needs. Confluence offers deep integrations with the full Atlassian suite, including Jira and Trello – making it easy to display issues for complete project transparency. Moreover, the platform also allows users to extend the tool’s capabilities with add-ons such as calendars, workflows and diagrams. If your team requires even further integrations, Atlassian marketplace hosts a wide suite of third-party apps at your disposal, not to mention integrations with SharePoint itself. Such integrations help you customise your instance’s appearance, as well as streamline team communication.
As for use cases, Confluence serves as an ideal knowledge base primarily used to capture, distribute and update technical information. Hosted on Atlassian Server, Conflence’s REST API is the native tool used to manage and retrieve data. Being particularly useful for recording procedural or troubleshooting information, dev teams can rely on Confluence to boost functionality for their app-building needs.
SharePoint exists within the Microsoft ecosystem, serving as a flexible content and document management solution. Much like Confluence, SharePoint has the resources to offer customers either a hybrid or self-managed approach, though many teams are seeking the advantages of moving to Office 365 Cloud.
By granting users access to all Office 365 applications, alongside a wide range of third-party integrations, teams often find SharePoint to be the answer to their content management needs. Such tight integration with Microsoft software may be convenient for businesses accustomed to using less development-heavy tools, focusing instead on the ease of document management that the system provides. While the integration with this mass of products could prove helpful to teams, it may also contribute to the complexity of the platform.
Automation and AI capabilities
In terms of automation, Confluence offers automotive capabilities to all Confluence Cloud and Premium members. Users can establish and activate complex rule-based workflows designed to automate repetitive tasks, such as creating pages for recurring meetings, archiving or deleting pages, and restricting pages to specific user groups. As for AI, Atlassian’s recent introduction of its native AI has transformed the ways in which users access the platform. Through Atlassian AI, teams can optimise their workflow, enhance productivity, and facilitate more efficient collaboration through smart recommendations. In addition to this, Atlassian is constantly working to expand its AI capabilities, so make sure to keep track of their newest developments.
SharePoint, on the other hand, utilises a tool named Power Automate as its native automation engine. Designed to automate repetitive tasks such as workflows, notifications and data synchronisation, the two platforms seem to be head-to-head with automation capabilities. Regarding SharePoint’s AI functions, they are very comparable to those of Confluence, offering capabilities such as intelligent insights to assist users with their working experience.
The bottom line
Both Confluence and Sharepoint offer a customisable and collaborative solution to your organisation’s needs, choosing between the two is simply a matter of preferences. Development teams may find more ease with Confluence, due to its strong integrations with Atlassian’s tools. In addition, the ease of use within Confluence’s functionalities makes it a perfect tool for smaller teams which may not have the capacity for extensive training. As for Sharepoint, its complex interface may be more suited to larger organisations looking to scale their operations. If you’re looking for our vote, we would side with Confluence, particularly due to the practicality of its functions and ease of use.
If you would like to know more about Confluence or its functionalities, make sure to contact our expert solutions team.
]]>
Recently, our solutions developers had the opportunity to attend the Atlassian Developer Day ‘24, hosted in London. This event served as a gathering for developers within the Atlassian community to collaborate, share insights, and learn from one another’s experiences.
In addition to this, Atlassian hosts a variety of workshops and talks throughout the day, designed to give developers further insight into their toolkit. A key focus of this Developer Day was Atlassian’s next-gen app development platform, Forge. Check out what our Senior Solutions Developer, Victor, and Solutions Developer, Abraham, have to say about the event.
Can you describe your overall experience at Atlassian’s Developer Day - what were some key highlights?
Abraham
My experience at the Developer Day in London was truly amazing. We had insightful sessions about Atlassian Forge, an engaging workshop covering the basics, and networking opportunities where we could ask the experts questions and share experiences with other developers from all over the world. The day went so fast and there were many more questions and things to discuss.
The event highlighted Atlassian’s dedication to promoting and supporting its relatively new development platform, Forge. It had a welcoming atmosphere, with exceptional care provided, especially given that it was free of charge. Attendees also received exciting goodies, such as stylish Atlassian t-shirts.
During the event, Karen White, Senior Product Marketing Manager of the Developer Platform at Atlassian, delivered a compelling presentation. She shared insightful data, graphs, and statistics regarding the evolution of the Atlassian marketplace and the significant influence of Forge. Another noteworthy session was conducted by Matt Muschol from Swiftix Software. He discussed his first-hand experience in online development education, particularly focusing on the Atlassian ecosystem. Muschol highlighted the distinctions between teaching Atlassian Connect, the older development platform, and Forge, the newer development platform, among other topics. The session was rich in detailed information and numerical data. Additionally, a workshop emphasised the common ground shared by all participants.
Overall, it was a day filled with innovation, learning, and meaningful connections.
Some key insights from this included:
Innovative Development Platform: Atlassian Forge stands out as a game-changer in the app development landscape, offering a streamlined and user-friendly experience for developers.
Community Engagement: The event provided a platform for networking and knowledge sharing among developers from diverse backgrounds, fostering a sense of community within the Atlassian ecosystem.
Marketplace Evolution: Insights shared by industry experts shed light on the evolution of the Atlassian marketplace and the transformative impact of Forge on app development and distribution.
Commitment to Innovation: Atlassian’s commitment to supporting Forge was evident throughout the event, showcasing their dedication to driving innovation and empowering developers to create cutting-edge solutions.
Victor
The event offered presentations catered for those new to developing with Forge. The main highlights for me were that I got to talk to both delegates as well as Atlassian staff.
There are a few projects that I have been having some trouble with, and I was able to ask the Atlassian staff about specifics and their recommendations. Conversely, Atlassian was able to question me about the usage of Jira as a solutions partner and provide me with a glimpse of what was in the pipeline.
It was also nice to be able to chat with other delegates, talking with those who have the same day-to-day issues as myself!
What emerging technologies/talking points were you most interested in prior to attending the event?
Abraham
Atlassian Forge took centre stage in the discussion. Forge represents a fresh approach to app development for Atlassian products, prioritising simplicity for developers. This streamlined process enables quicker and more targeted task completion, appealing not only to new developers but also to individuals with limited development expertise, like Jira administrators. The emphasis is on making tasks “easy” for all.
Additionally, there were certain pain points that I was eager to address, such as Forge rate limitations and time outs, best practices, and more.
AI, being a trendy topic, was another point that caught my interest. However, it was only briefly discussed without delving into details.
Victor
It was interesting to learn how the developer ecosystem has evolved and changed over just a year. There was a deep dive presentation into the technical elements of Forge; this was a good reminder of how powerful Forge is.
What had been your prior experience in building Atlassian apps?
Abraham
My prior experience in building Atlassian apps has been quite rewarding. I have developed apps using the older Atlassian Connect platform, which provided valuable insights into the intricacies of app development within the Atlassian ecosystem. However, Atlassian Forge is a whole new level, a revolutionary new development platform that simplifies the app-building process significantly. Forge offers a seamless experience with features like built-in hosting, development environments, storage, and security, making it incredibly user-friendly for developers of all levels. The transition to Forge represents a significant leap forward in enhancing the developer experience and expanding the possibilities for creating innovative apps within the Atlassian ecosystem.
Victor
I have personally developed multiple apps in Server and also a few apps using the Connect framework and Forge platform for Cloud. Some of these are in the Atlassian Marketplace, but a number of them have been developed for private internal or direct customer use.
Can you share your thoughts regarding Atlassian’s app development platform, Forge?
Abraham
In the realm of app development, the conventional hurdles of configuring environments, managing storage, setting up databases, implementing security measures, ensuring scalability of the application, and organising hosting, often overshadow the core objective of crafting a functional and user-friendly application. This is where Forge emerges as a beacon of innovation, revolutionising the development landscape with its seamless approach. By streamlining the intricate setup processes that traditionally consume valuable developer time and energy, Forge liberates creators to focus wholeheartedly on the art of app creation. With Forge, the journey from concept to execution is marked by efficiency, empowering developers to channel their creativity without being entangled in the complexities of infrastructure management.
I can’t help but speculate whether other major tech companies will eventually follow in the footsteps of Forge.
Victor
Forge provides a runtime, UI, and integrations directly in the Atlassian ecosystem. It is clear that Atlassian has put a lot of thought into the developer experience and removing the technical barriers that once made developing in the Cloud a lengthy process.
Forge is an evolving platform and will continue to grow in capability. Currently, the extension points are quite broad and should meet most use cases. It has been interesting how the UI has evolved, specifically around UI Kit; in its current form, it is much more responsive and user-friendly than UI Kit 1.
What are the most valuable insights you gained during this Atlassian event?
Abraham
The insight that stood out the most was the exceptional quality of pastries in London! Only kidding! On top of boosting my confidence in myself and the product, it was very valuable to see a clear path to the future of app development for Atlassian.
We received insightful responses from experts like Robert Massaioli, Atlassian’s Engineering Manager, and Dugald Morrow, Atlassian’s Developer Advocate, who are highly involved in these subjects on a worldwide scale. It assisted us in understanding the reasons behind certain decisions made and exploring potential alternative choices.
To summarise, an extraordinary and invaluable event that I am extremely grateful to have been able to attend.
Victor
They revealed their plans with the latest acquisition, Rovo, and that they will be allowing the developer community to extend its capabilities soon.
Atlassian puts a lot of consideration into Forge. They request feedback in the developer community forums and only implement changes if it does not adversely affect their partners.
Looking to Atlassian’s future
It’s clear that there are many exciting things in store for Atlassian, particularly in terms of its newest platform, Forge. Make sure you stay updated with all the newest Atlassian updates through our blogs.
]]>
Trello, an Atlassian tool and favourite amongst a variety of business teams can be used to enforce this strategy and help your team bring your customer relationships to the next level. With the help of Trello, companies can create exceptional customer experiences that drive loyalty and growth. Read more to discover how you can utilise Trello’s CRM capabilities to their fullest potential.
Why does Trello work for CRM?
Customer Relationship Management (CRM) is a business strategy that involves the use of software to manage interactions with current and potential customers. This includes a range of activities, technologies, and processes that companies use to monitor and analyse customer interactions throughout the customer lifecycle. This is where Trello steps in; an otherwise complicated process is simplified with Trello’s CRM-specific functionalities.
Wondering where to begin when introducing your CRM process to Trello? Here are a few steps to get you started:
1. Define your sales process
With the help of Trello’s interactive boards, you can efficiently manage your sales process by organising it into different stages and keeping track of your leads all in one place. Although every business has its unique way of developing and handling client relationships, there are some common stages that you can incorporate into your board.
Each column on your board will represent a separate stage in your sales pipeline, such as ‘Lead’, ‘Follow-up’ and ‘Closed’. Clients are represented through cards – which can be moved through the board as you progress through the sales pipeline. As these cards move through their pipeline, you can assign statuses to them, such as ‘in progress’ and ‘complete’ to indicate their progress within the sales timeline.
2. Populate cards with client information
Once you have a clear outline of your sales pipeline, you can begin to add client details to your cards. These cards can include important information such as main contact details, notes from previous interactions, dates of previous follow-ups or any other information that might help you build a stronger relationship with the client.
With Trello’s advanced checklists, activities within cards can also be given due dates and levels of priority to help you better manage your client interactions. These cards allow you to visually keep track of your progress and the current status of each individual client. If you prefer to use Jira for sales tasks, our application Crumbs provides a single source of comprehensive customer data.
3. Add automation and integrations
Trello’s native features give you the option to automate time-consuming routine tasks using your own triggers and conditions. This can be achieved by setting up rules tailored to your specific triggers and conditions. For instance, you can create rules that automatically move cards based on certain criteria, such as ordering tickets based on the time since last contact, or whether an initial meeting has been held. By doing so, you can save a significant amount of time and effort that would otherwise be spent on these manual tasks. With Trello’s automation capabilities, you can streamline your workflow and focus on more important tasks.
Trello offers a range of ‘Power-Ups’ that can help you streamline your work and boost productivity. These features can be used to integrate with other tools, add custom fields, set up automation, enable advanced search, and much more. Some popular third-party integrations supported by Trello are Slack, Microsoft Teams and CRM-specific integration Crmble.
4. Collaborate with ease
In addition to the features above, Trello also offers a multitude of collaboration functions, designed to adapt to your team’s needs. The ticketing system allows you to assign tasks to specific users, ensuring that each step of a process is handled by the appropriate team member. Additionally, a ‘blocked’ column can be included to indicate tasks that cannot proceed until a user reviews them, ensuring that no ticket is overlooked. Another way to facilitate collaboration is by tagging people in on questions. This feature allows team members to easily ask for assistance or input from their colleagues, which can help to resolve issues quickly and efficiently. By utilising these collaboration tools, teams can work together seamlessly and effectively to provide support to their customers and improve their sales process.
Looking to the future of CRM with Trello
Trello provides a great solution for those looking for a simple way to manage their client information and sales pipeline. However, depending on the needs of your team, Trello may not provide all the features required for a comprehensive CRM solution. For instance, Trello does not offer granular data on sales activities, such as lead sources, conversion rates, and revenue generated by each sales representative. If your team is looking for a more in-depth alternative to Trello, Atlassian’s Jira provides a wide range of sales board functionalities. We would still highly recommend Trello for your standard CRM solutions, and we’re excited to see any new features that Trello might introduce in the future.
If you would like to find out more on how you can utilise Trello for your CRM solutions, get in touch with our Atlassian Platinum-certified team of experts.
]]>
How Notion’s new features compare to Confluence
In the current climate of software development, it is vital for teams to have the means to collaborate effectively. Faced with an overwhelming choice of tools in the current market, teams need to consider the right fit for them and their specific needs. This is where Notion comes in, a newer platform that has been gaining traction in recent years. However, you may be wondering how this newer tool stacks up against Atlassian’s Confluence, an industry-standard platform.
From agile development to product roadmapping, Notion introduces a versatile workspace that, similarly to Confluence, uses AI to adapt to a team’s unique processes and workflows. The new update has introduced exciting changes to this new tool’s capabilities, read on to discover how these new features compare to Confluence.
Automation with database buttons
Tracking progress can sometimes slow down your team. Tasks such as approving a document or escalating an issue, may require multiple steps, which can lead to slower progress. With the new update, Notion has introduced a feature that can streamline your team’s workflow and boost efficiency. By using database buttons, you can initiate a series of actions with just one click. This not only saves you time when performing repetitive tasks but also makes it easier for everyone on the team to complete the correct steps.
This follows a similar workflow to Confluence, where automation rules are made by combining different components. These include triggers, conditions, branches and actions, which work together to build your end automation. Users are also able to create rules from a template which allows you to change pre-selected components within a rule chain. When it comes to AI automation, Confluence and Notion are head-to-head, both offering their native AI functions that analyse your workflow and suggest automation according to their findings.
Navigating tasks
Notion’s Home feature is designed to make your workspace experience more streamlined and efficient. With this feature, you can access all your essential content from across your workspace in one convenient location. This includes everything from assigned tasks to important notes and documents, as well as other relevant information. This feature also provides a more organized and structured approach to managing your tasks, making it easier to prioritise and track progress.
While Notion’s Home feature boasts many collaborative features, Confluence seems to have a one-up on the newer platform in terms of integration capabilities. Integrations with other Atlassian products, such as Jira, Bitbucket and Trello are a clear pull for larger teams looking to boost their collaboration. In addition to this, Confluence has a larger variety of information storage with features such as spaces, pages and templates designed to be customised to the needs of your team.
Both Notion and Confluence have strong Home features that are designed for optimising your collaboration and workflow. However, where Confluence stands out is the size of its user community. As a well-established platform in the collaborative space, its wealth of users allows teams to share resources, learn new features, and work together to solve issues.
Performing tasks with ease
Notion has introduced a new feature that allows you to easily reply, archive, or mark notifications as read without having to even open the Notion app. This not only saves you time but also makes it easier to manage notifications. By having quick access to these options, you can efficiently manage your notifications and stay focused on your work without getting distracted.
Currently, Confluence does not offer the ability to reply, archive, or mark notifications, and it appears that Atlassian has no plans to implement limited actions, possibly due to security and usability concerns. However, users benefit from a vast set of features within the app itself, simply needing to open the Confluence app to access, create, edit, and collaborate on pages.
Upcoming features
With this multitude of new features available, it’s clear to see that Notion is catching up with classic workspace platforms such as Confluence. The recent rollout of Atlassian AI has shown users that Atlassian is always working to keep up with development trends. While Notion is a platform to watch, Atlassian tools remain tried and tested, and deeply established within the software community. However, it is interesting to see the features being introduced in a newer platform, and how this could potentially impact the features available in Atlassian products down the line.
If you would like more information on how Atlassian products compare to other project management tools, get in touch!
]]>
We are excited to share the results of our litter-picking challenge, which we participated in as part of our community giving strategy. This initiative, driven forward by our community champions Aleks and Abraham, goes hand-in-hand with New Verve’s strong emphasis on having a positive impact on society. As part of our business philosophy, we strive to lead several initiatives that allow individuals to choose their own way of ‘giving back’ to the wider community.
OnHand, a company that facilitates on-demand volunteering, provided us with the basis of our challenge, alongside a simple way of tracking our progress. Through the months of November, December and January, our team collected 20.5 bags. This active form of volunteering was a great opportunity for our team to get together and trial a new form of giving to their community. As our team is based all over the UK, we were able to bring the benefits of our challenge to a variety of different communities. Through tracking our progress and encouraging each other through Slack, this initiative allowed us to work together and celebrate our achievements as a team. Ultimately, taking part in something community-orientated has brought us closer not only as a community but also as a team.

Below, one of our community giving champions, Aleks, shares her experience of organising and running the OnHand initiative.
What made you choose this volunteering opportunity?
I decided to complete this volunteering opportunity because it was something I could do with my family and see a big, immediate impact on my surrounding area and community. It was also a great opportunity to talk to my son about the environment, recycling and importance of minimising the amount of litter we produce.
How do you feel the initiative impacted our team and the wider community?
I think this initiative showed people that even small acts can have an impact. I feel it also made people think harder about how much we consume and dispose. Talking to my colleagues, we all shared a sense of pride for doing something that will keep our local areas clean. A few people received praise from members of the public for picking the rubbish and how much more pleasant it is to walk around clean areas. Some of my friends were inspired by how clean our local area was and they organised litter-picking with their children around their local green spaces.
What did you learn from your experience?
I learned that you can have a lot of fun with your friends and family while doing something good for the planet and community, it’s just a matter of attitude. Initiatives like this help people to get inspired and push them to do more for the environment than they would normally do.
We would like to thank the effort and consideration that our community giving champions put towards this initiative, alongside all the hard work from our team! If you would like to find out more about how we strive to help our community as a team, get in touch.
]]>
With AI tools skyrocketing in popularity over the last year, it’s no surprise that Atlassian has now rolled out a suite of new AI-powered features for users. Atlassian Intelligence is the new powerup that works across Jira, Confluence, and more. Keep reading to learn more about Atlassian Intelligence, how to use it, and how to maximise efficiency.
2023: The Year of AI Headlines
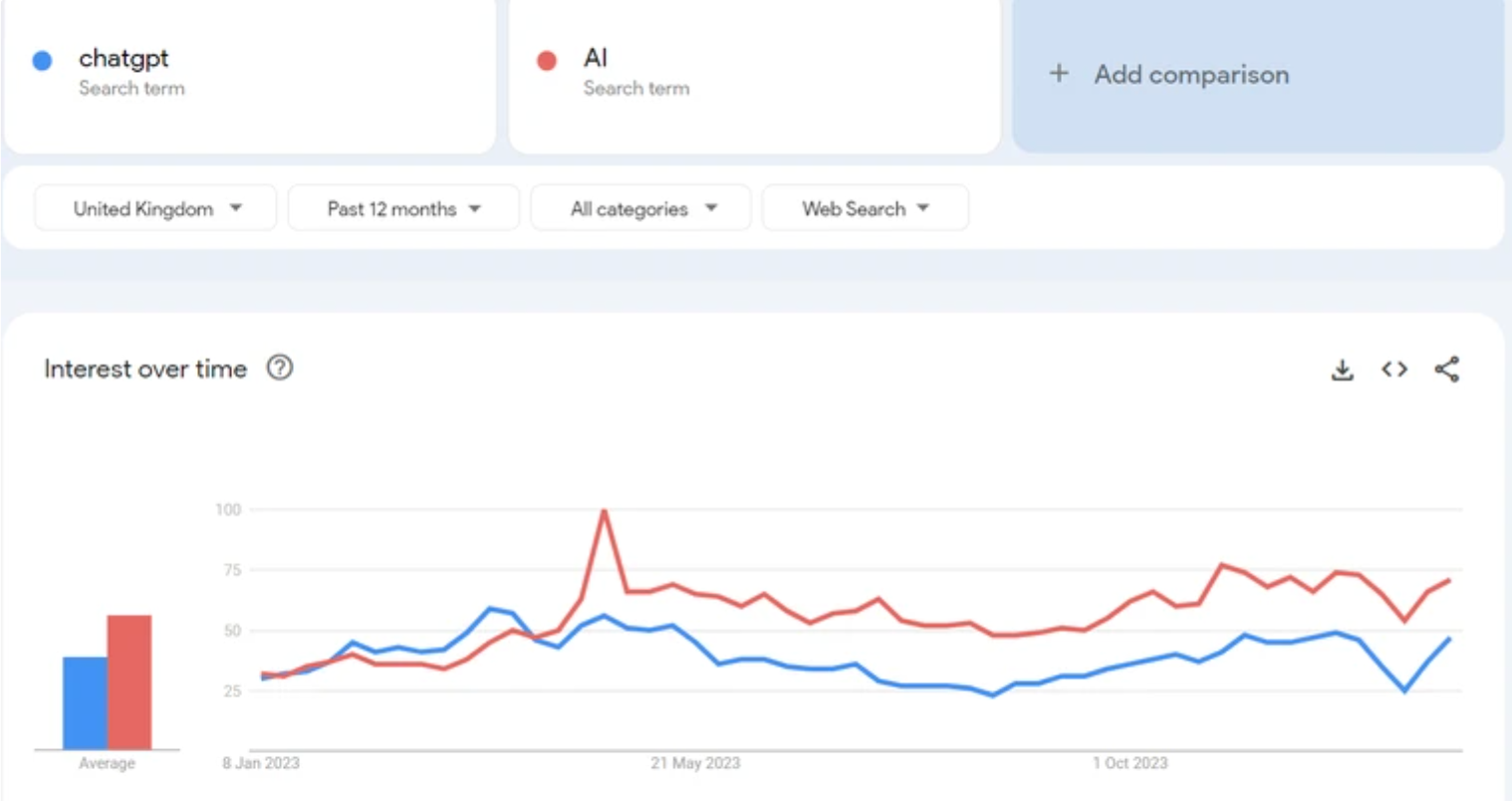
Back in early 2023, Atlassian announced its intention to bring AI tools to its already impressive stack. A beta program was opened and the uptake among admins was high; users were keen to put the brand-new tools through their paces. This announcement came at a perfect time, as Google Trends reported searches for ChatGPT, AI and related queries peaked in April 2023.
Over the course of 2023, AI-based tools continued to make headlines - with both positive and negative connotations. Throughout the year, the ethics of these tools have also been the topic of much debate, as well as concerns about safety and privacy. In October of 2023, a precedent-setting agreement was reached with the Writers Guild of America (WGA) after one of the longest strikes in Hollywood history. The agreement made specific references to the use of AI tools and the risk that they pose to writers’ job security.
In the world of academia, further concerns were raised over plagiarism and unethical conduct using AI tools. Reports of students using ChatGPT to write assignments and the counter-measures that could be put in place showed that technology was advancing at a faster pace than regulation. Artists also protested their works being used to train image-generating AI tools.
These discussions made it clear that AI could be useful in a number of real-world applications, but only with the right safeguards. This was the backdrop for the release of Atlassian Intelligence, which was touted as a ‘human-AI collaboration tool’. The ethos of the tool is that it is to be used as an additional colleague, which makes perfect sense for the highly collaborative Atlassian stack.
Atlassian Intelligence Features
As Jira and Confluence are both geared towards collaboration and maximising efficiency, Atlassian Intelligence aims to take this a step further. One of the factors that make this possible is Atlassian’s back catalogue of organisational data and expertise.
The tools are powered by OpenAI, leveraging data already stored in your Jira and Confluence space. This gives users the chance to harness contextual cues when asking questions.
Confluence is an excellent collaboration tool, but if you have a lot of documentation or are unsure of where certain definitions or reports live, then Atlassian Intelligence can do a lot of heavy lifting for you. The contextual definition icon will appear when you highlight words within your Confluence space. It will then fetch information from across your documentation to serve up that definition - for example, defining a company-specific acronym. You can even use it on other users’ names to discover who they are and what they do within your organisation.

The search bar in Confluence can now also be used to ask company-specific questions. Using the documentation, Atlassian Intelligence can answer questions about a variety of topics - such as the launch date of a product, whether a decision was made in a meeting, and more.
Likewise, the summarise feature can save precious time when reading through intensive documentation, as the AI works to pick out the most important information. One feature we’d like to see added to this tool would be a summary of changes from document versions - this would help highlight which updates had been made in a newer version.
Writing Assistance
In terms of generating writing, Atlassian Intelligence can author documentation and comments too. There are a plethora of options available in edit mode in Confluence or when replying in tickets in Jira. Summarise or improve what you’ve written, look for action items or change the tone of your message with just a click.
As we write this blog in Confluence, we figure it’s only fair to ask Atlassian Intelligence to tell us more about it. The following paragraph has been written by Atlassian Intelligence:
“Atlassian Intelligence is a helpful assistant developed by Atlassian. It provides concise responses to user requests using the provided context only. Atlassian Intelligence can help you write by providing suggestions, tips, and guidance on various writing topics. It can assist with grammar and spelling checks, offer ideas for structuring your content, provide examples of effective writing styles, and even suggest improvements to make your writing more concise and engaging. With Atlassian Intelligence’s assistance, you can enhance your writing skills and create high-quality content.”
Our team have found these language and summarisation skills to be the most useful features of Atlassian Intelligence. When communicating on Jira tickets, Atlassian Intelligence has been assisting our teams in ensuring they provide all the required information, with the right tone and in a concise manner.
Technical Features and Virtual Agents
On the more technical front, Atlassian Intelligence can also convert natural language to JQL and SQL. This allows technical experts and less technical users to find issues and dependencies in Jira Software and Jira Work Management. By using natural language to SQL, more users can gain insights into Atlassian Analytics - expanding access from data science teams. This can be used by business teams to gain knowledge on customer service metrics, issue tracking, team health, and more.
Finally, virtual agents are now available. These chatbots can currently run scripts, raise issues, and report metrics. Their next power-up will be the ability to review code within Bitbucket. While this won’t replace colleagues who review code, they will make that job easier by scanning syntax, generating pull requests, and aligning code conventions.
Safety, Privacy and Security with Atlassian Intelligence
Many of the questions we have around the use of AI relate to our safety, privacy and security. This is especially pertinent when dealing with sensitive or copyrighted information stored in Confluence or Jira. Atlassian has put together a trust page, specifically outlining how Atlassian Intelligence uses data.
The information that the AI model uses is sent over secure channels and not used to train Atlassian Intelligence in any other instance. Your data is still secure and private, without any additional risk while using Atlassian Intelligence.
Atlassian Intelligence will also respect permissions, so users who don’t have access to pages will not see data generated by those pages. If you’re concerned about data residency, Atlassian Intelligence respects this and won’t send any data outside of your region.
How to Enable Atlassian Intelligence
Admins have the power to enable Atlassian Intelligence in the existing admin panel at admin.atlassian.com. It’s simple and you have the option to restrict access to certain sites or products.
Atlassian Intelligence has the power to help your team to be more efficient and productive, if used correctly. While we’ve used summaries and editing, we’d always caution ensuring that you check and double-check any outputs. As with any new technology, there are limitations and areas that will be improved over time - so don’t hit send on that Atlassian Intelligence authored comment before giving it a human review.
Interested in finding out more about our services? Contact us today.
]]>
Jira, a powerful project management tool developed by Atlassian, is typically used by software teams as a means of software development and bug tracking. Due to the versatility of the tool, it empowers a variety of teams to efficiently manage tasks, projects and workflows. With the advanced collaborative features available, many teams rely on Jira for the smooth execution of their projects.
Whether you’re using Jira for software development, project management, or any similar process, following best practices can significantly enhance your team’s productivity and reduce roadblocks. These best practices are designed to help your team make the most out of Jira’s features and capabilities, ensuring that no matter the task, it can be carried out efficiently.
1. Define goals and objectives
Before looking into setting up your Jira instance, it’s crucial to have a clear understanding of your project’s goals and objectives. With the flexibility that the tool offers, it can be used for a wide variety of project tasks, therefore, it’s vital that the team understands the overarching goals of their project. This clarity will allow your team to build a Jira configuration that best aligns with their needs, and as a result allows them to complete objectives.
2. Train users
By providing Jira training and resources to your team members, you can ensure that they can navigate the tools confidently and make the most out of its capabilities. Since Jira offers such a wide array of features and functionalities, many users may first be intimidated by just how extensive the tool is. However, with the appropriate training, you will ensure that team members can navigate Jira confidently and use the functions to their advantage.
3. Customise workflows
Teams are able to reflect their specific workflow stages through tailoring features such as statuses, transitions and permissions. As team needs change every day, it is vital that users take the time to reflect this within a workflow in order to prevent potential roadblocks. In addition to this, taking the time to customise your workflow facilitates a collaborative environment, as each team member can see the status of everyone else’s workload.
4. Use agile methodologies
Jira supports any agile methodology, such as Scrum or Kanban, allowing teams to follow along with the built-in features to streamline their work. Tools such as agile boards, backlogs, and sprint planning are available to assist your team with managing their projects and ultimately delivering high-quality results in a collaborative environment.
5. Name and organise issue types
A project typically consists of many moving parts, which can make it difficult to track progress at times. By using Jira’s functionalities to set up naming rules for issues and organising them into standardised types, your team create consistency within the process. By ensuring that each issue is organised into a category, your team can gauge the importance of said issue and work more efficiently.
6. Integrate with other tools
While Jira boasts a mass of features that your team can take advantage of, you should always look into the integrations available. These integrations allow you to combine tools that address the specific needs of your team, for example, an integration between Trello and Jira allows teams such as software and marketing to collaborate. This has the potential to streamline workflows and ensure that information flows between systems.
7. Automate repetitive tasks
Jira offers easy-to-use automation functions that allow teams to automate tasks that are repetitive and time-consuming. By automating tasks, you not only give team members the opportunity to spend their time on higher priority tasks, but also reduce the risk of human error. An example of such automation could be issue assignment, where you can create rules that assign issues to appropriate team members based on specific criteria.
8. Add descriptions and checklists
Teams should seek to communicate effectively through detailed issue descriptions and checklists. Including detail within your descriptions, such as the appropriate documentation and contacts, reduces the need for back-and-forth communication and fosters a more streamlined process. In addition to this, checklists are a great way for a team to clearly display process steps in an organised and transparent way.
9. Keep backlog organised and updated
As a project progresses, many teams may be tempted to focus on their current issues rather than updating their backlog. However, you should not underestimate how important a backlog is – it’s a place where you can list ideas, implement tickets and add enhancements. Without a well organised backlog, your team may struggle to follow their initial goals and objectives and end up facing roadblocks along the way.
10. Make use of reporting features
Jira’s reporting and dashboard features allow your team to gain valuable insights into their progress and performance. Through visualising the information that’s relevant to the teams objectives, you can gain a better understanding of progress and allows you to identify roadblocks, allowing you to enhance your team’s efficiency as a result.
While these best practices are important, they need to be adapted to suit the needs of your team and the nature of your project. By regularly assessing your project and keeping up to date with challenges, Jira will act as a valuable asset for your teams collaboration.
If you would like to learn more about how Jira can help your team, get in touch. Our expert solutions team can answer any questions you may have.
]]>